本文主要想探究的是我们平时说的IO系统调用与inode,文件系统等之间的交互,或者说,在做文件IO时候,有那些底层的数据结构参与进来。
在讲具体的系统调用之前,先要简单了解几个概念
文件系统
文件系统可以简单的理解为数据结构+方法
数据结构:文件系统以一种怎样的结构来组织其存储的数据
方法:open(),read()等调用如何与数据结构打交道
一个简单的文件系统一般有这几部分
- inode table记录文件的metadata,主要有文件的权限,用户,创建时间,文件所对应blocks
- data block 存储实际问文件内容
- inode bitmap 记录inode table 分配情况位图用0/1来表示对应项是否分配
- data bitmap 记录data blocks 分配情况
- superblock 记录了整个文件系统的一些信息,比如inode个数,data blocks个数,inode table 起始地址。当文件系统
mount()superblock被加载到内存。
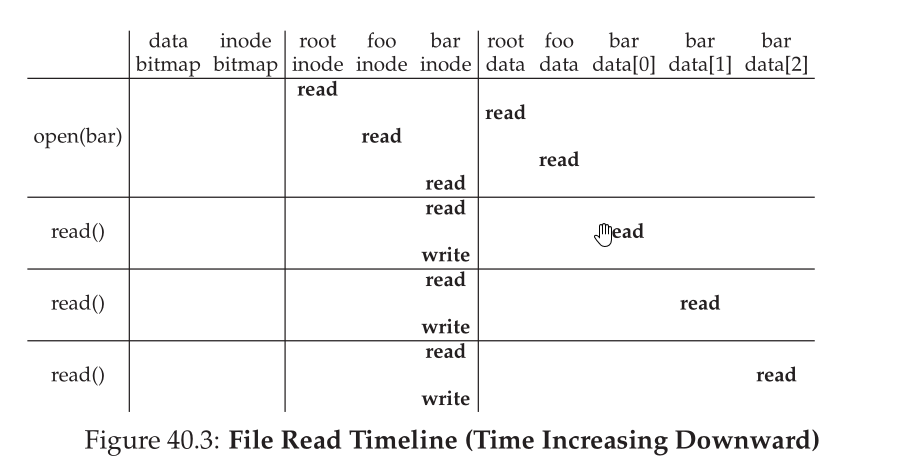
read()
以/foo/bar 为例,假设文件大小为4kb
首先open("/foo/bar",O_RDONLY) 需要找到文件bar对应的inode,具体的做法是按照文件路径遍历,通过目录中存储的文件名->inode-number来找到文件bar对应的inode。
将文件对应的inode加载到内存,做权限检查,比如文件读写属性。每个进程中都有一个open-file-table,系统为打开的文件分配文件描述符。
一旦文件打开之后,read()按照顺序从第一个block开始读取,具体来看需要读取inode来获取区块位置信息,更新inode中last-access-time。更新open-file-table中的file offset。
打开一个文件所涉及到的IO操作与文件路径长度成正比。每次通过父目录中的data-block来获取inode-number,用来在inode table查找对应的inode,通过inode来查找data-block位置。 因此每多添加一层目录就会有额外的两次IO.
下面的图直观的说明这一过程