《OSTEP》 内存虚拟化部分小结
地址空间
为什么引入了虚拟地址?
- 使得编程简单,每个应用进程有自己很大一片的地址空间,不用担心代码,变量存放到哪里
- 提供了进程之间的保护和隔离;如果我们直接操控物理内存,那么很可能由于进程一个不小心override导致其他进程崩溃
举个例子两个进程A,B 都有自己的地址空间,eg. 对0x100访问,由于虚拟地址的映射他们对应的物理地址不同。
设计一套虚拟内存需要满足满足那些目标?
透明; 对于编程者而言,我们应该是感知不到虚拟地址到物理地址之间的转化,操作系统和硬件在后面帮我们做了地址转化的这些工作
高效; 引入虚拟内存,空间角度上来看使用额外很多的内存来存储辅助数据结构,时间上不能导致程序运行变慢
保护/隔离;这个我觉得是最为重要的,程序装载到内存中不能够影响到其他进程。
具体来看,虚拟内存实现机制,分段,分页下如何做进程间保护?
简单地址翻译
作者先做了一些假设,对虚拟内存系统设计做了一些简化,然后慢慢放宽条件,逐渐模拟一个真实场景下的虚拟内存系统。这样能够让读者循序渐进体会到系统设计面临的问题,然后慢慢引入新的方案来改进。
一开始作者假设
- 虚拟地址空间连续存放到物理内存
- 地址空间大小不超过物理内存&&每个进程地址空间相同
硬件支持地址翻译
在上述假设下,有了基于硬件支持的动态重定位来做地址翻译通过硬件寄存器支持 base+limit
地址转化: physical address = virtual address + base
limit用来做权限保护,如果虚拟地址超出了limit,程序将终止。
之前经常听到的MMU,用来做地址转化的硬件单元,这里提到的base,limit寄存器就是MMU的一部分,当然后面为了做更加复杂的地址翻译,MMU还有一些其他硬件的支持。
从操作系统角度,基于上述虚拟内存的实现方案,有几个问题要解决
- 进程创建时,分配与地址空间对应的物理内存
- 当进程结束时,回收内存
- 进程切换,上下文保存;这里只需要保存一对base-limit寄存器
小结
base+bound 的地址转化方案
优点
在硬件支持下起来很高效快速
提供了进程间的保护隔离
缺点
- 进程空间的整个映射到内存导致了内部碎片(heap,stack)
分段机制
基于单个base-limit寄存器将整个地址空间存到了内存造成了内存的浪费,我们分析主要的原因在于,stack,和heap的不确定,基于此,我们为什么不能够在单对寄存器的基础上,对code,data,stack,heap 都分配一对寄存器
我们经常见到的段错误(segment fault)就是访问非法地址,超出了bound的范围。
段表的引入带来了一个问题,如何确定访问哪一个段对应的寄存器?
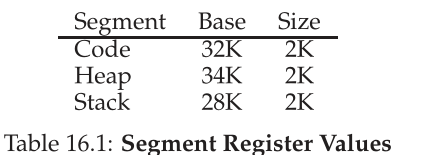
显示的做法时用虚拟地址前几个bit来标识,如下图
分段机制下地址转化伪码
1 | // get top 2 bits of 14-bit VA |
按段加载还有一个好处使得段共享成为可能,比如将代码段设为只读,进程仍然认为访问的是私有地址空间,这样也不会破坏进程间的隔离。
小结
好处:
减少了内部碎片,内存浪费
代码段等可以共享
问题:
大小不一的段可能导致外部碎片
内存不能做到按需分配
产生外部碎片的原因在于,之前按照整个地址空间加载,并且进程地址空间大小一致,这样就可以将内存看作是一个大的数组,每次分配都是一个slot单位,现在按照段分配,虽然避免了内部碎片产生,但是由于每个段大小不一样,在内存的频繁分配与释放,就可能产生外部碎片,一些小的内存块就不能够得到利用。
空闲物理内存管理
我们在C中分配释放内存如下
1 | void *malloc(size_t size); |
会发现当我们释放内存时候,只是给了起始地址,没有指定大小,那么系统怎么知道要释放多少了?
分配器用额外的头部信息来记录分配内存的大小,魔数用来做完整性检查。因此当我们申请N字节大小内存,实际分配了N+sizeof(header)
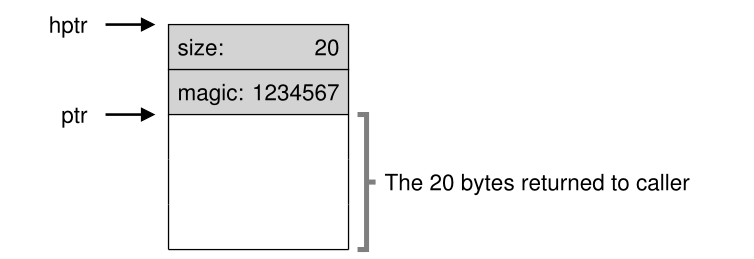
伙伴系统
free memory is first conceptually thought of as one big space of size 2N. When a request for memory is made, the search for free space recursively divides free space by two until a block that is big enough to accommodate the request is found (and a further split into two would result in a space that is too small).
分页机制
我们说分段导致了外部碎片产生,根本原因在于段的大小不一,分页机制通过将地址空间划分为固定大小的地址单元(eg.4k)来解决这个问题。
每个进程有自己的一个页表,记录了虚拟页号和物理页号的对应关系。常见的地址映射如下
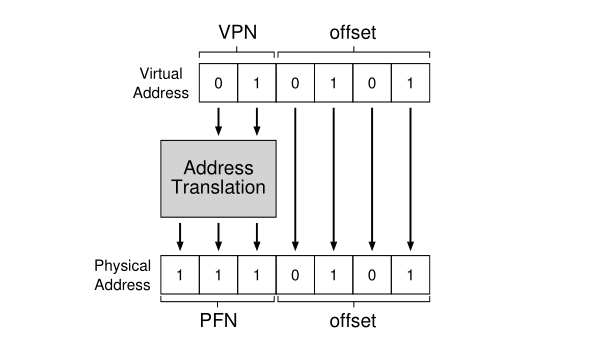
实现页机制有几个问题
1.页表存在哪里?
2.每一个页表项具体有什么内容?
对于32bit地址空间,假设一个页表项4byte, 整个地址空间页表需要4M,每个进程有自己的页表,因为页表很大,不可能像段机制那样通过CPU的寄存器来存,因此我们的页表是直接存到内存里面的,刚刚分析一个页表就是4M,这个很恐怖,如果有上百个进程,光是页表就消耗了几百兆内存,因此这一部分后面是需要优化的。
X86下一个页表项的内容如下,有几个flag需要注意下
- P:存在位。为1表示页表或者页位于内存中。否则,表示不在内存中,必须先予以创建或者从磁盘调入内存后方可使用。
- R/W:读写标志。为1表示页面可以被读写,为0表示只读。当处理器运行在0、1、2特权级时,此位不起作用。页目录中的这个位对其所映射的所有页面起作用。
- U/S:用户/超级用户标志。为1时,允许所有特权级别的程序访问;为0时,仅允许特权级为0、1、2的程序访问。页目录中的这个位对其所映射的所有页面起作用。

由于页表位于内存,带来的后果就是我们对于一条指令的执行将额外增加一次内存访问(地址翻译),伪码如下
1 | VPN = (VirtualAddress & VPN_MASK) >> SHIFT |
小结
好处:
固定大小内存单元,避免外部碎片
相对分段内存使用灵活
缺点
页表占用内存过大
访问太慢(相比直接内存访问,多一次内存访问)