总结影响网络收发包的一些套接字选项,对一些概念可能理解不对,希望大家多多指教。后面会持续更新ing。
[TOC]
套接字属性设置
通过setsockopt我们可以设置套接字的一些属性,函数原型如下
1 |
|
其中level 参数设定的套接字属性使用范围,SOL_SOCKET表示用于通用套接字,IPPROTO_TCP 用于tcp协议,IPPROTO_IP 用于IP协议。
下表是《APUE》中给出的一些通用套接字设置选项
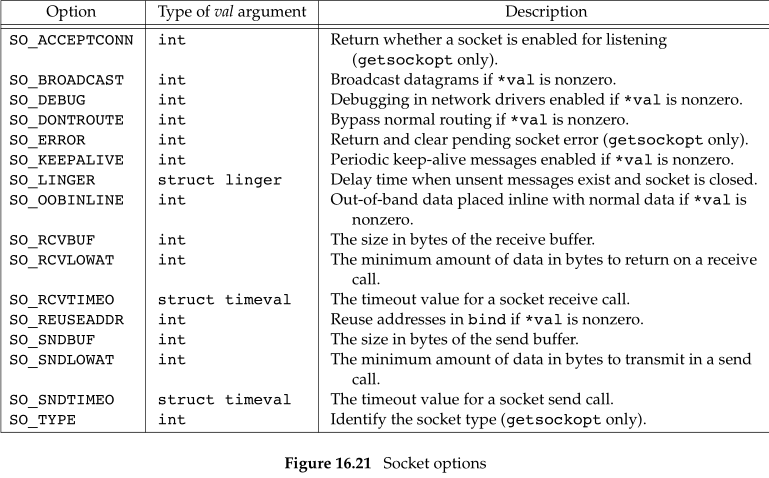
SO_KEEPALIVE
为什么需要保活?
在tcp连接双方,建立连接之后,很长时间没有交换数据,在这种长时间没有数据交换情况下,双方不知道对方状态,交互双方都有可能出现掉电、死机、异常重启等各种意外,当这些意外发生之后,这些TCP连接并未来得及正常释放,那么,连接的另一方并不知道对端的情况,它会一直维护这个连接,长时间的积累会导致非常多的半打开连接,造成端系统资源的消耗和浪费,为了解决这个问题,在传输层可以利用TCP的保活报文来实现。
- 探测连接的对端是否存活
在应用交互的过程中,可能存在以下几种情况:
客户主机依然正常运行,并从服务器可达。客户的TCP响应正常,而服务器也知道对方是正常工作的。服务器在两小时以后将保活定时器复位。如果在两个小时定时器到时间之前有应用程序的通信量通过此连接,则定时器在交换数据后的未来 2小时再复位。
客户主机已经崩溃,并且关闭或者正在重新启动。在任何一种情况下,客户的TCP没有响应。服务器将不能够收到对探查的响应,并在75s后超时。服务器总共发送10个这样的探查,每个间隔75秒。如果服务器没有收到一个响应,它就认为客户主机已经关闭并终止连接。
客户主机崩溃并已经重新启动。这时服务器将收到一个对其保活探查的响应,但是这个响应是一个复位,使得服务器终止这个连接。
客户主机正常运行,但是从服务器不可达。这与状态2相同,因为TCP不能够区分状态4与状态2之间的区别,它所能发现的就是没有收到探查的响应。
利用保活探测功能,可以探知这种对端的意外情况,从而保证在意外发生时,可以释放半打开的TCP连接。
防止中间设备因超时删除连接相关的连接表
中间设备如防火墙等,会为经过它的数据报文建立相关的连接信息表,并为其设置一个超时时间的定时器,如果超出预定时间,某连接无任何报文交互的中间设备会将该连接信息从表中删除,在删除后,再有应用报文过来时,中间设备将丢弃该报文,从而导致应用出现异常,这个交互的过程大致如下图所示:
默认情况下tcp的保活是关闭的,需要我们自己打开。
1 | optval = 1; |
全局修改探测活参数
1 | echo 600 > /proc/sys/net/ipv4/tcp_keepalive_time //超时时间 |
通过系统调用对单个进程修改
对应到的几个套接字选项如下
TCP_KEEPCNT: 对应到探测报文发送次数;
TCP_KEEPINTVL: 探测报文发送间隔
TCP_KEEPIDLE: 超时时间
TCP层的保活和应用层保活对比
KeepAlive通过定时发送探测包来探测连接的对端是否存活, 但通常也会许多在业务层面处理的,他们之间的特点:
- TCP自带的
KeepAlive使用简单,发送的数据包相比应用层心跳检测包更小,仅提供检测连接功能 - 应用层心跳包不依赖于传输层协议,无论传输层协议是TCP还是UDP都可以用
- 应用层心跳包可以定制,可以应对更复杂的情况或传输一些额外信息
KeepAlive仅代表连接保持着,而心跳包往往还代表客户端可正常工作
SO_LINGER
1 |
|
数据结构
对应的val是一个结构体
1 |
|
一个简单的使用例子
1 | struct linger lin{0,1}; |
linger打开与否,以及不同时间的设置,可能导致不同的关闭结果。
三种断开方式:
- l_onoff = 0; l_linger忽略
close()立刻返回,底层会将未发送完的数据发送完成后再释放资源,即优雅退出。
- l_onoff != 0; l_linger = 0;
close()立刻返回,但不会发送未发送完成的数据,而是通过一个RST包强制的关闭socket描述符,即强制退出。
- l_onoff != 0; l_linger > 0;
close()不会立刻返回,内核会延迟一段时间,这个时间就由l_linger的值来决定。如果超时时间到达之前,发送完未发送的数据(包括FIN包)并得到另一端的确认,close()会返回正确,socket描述符优雅性退出。否则,close()会直接返回错误值,未发送数据丢失,socket描述符被强制性退出
SO_LINGER实现原理
1 | case SO_LINGER: |
程序调用函数close()关闭套接口时,与此相关的函数调用路径如下:sys_close() -> filp_close() -> fput() -> __fput() -> sock_close() -> sock_release() -> inet_release() -> tcp_close()
1 | int inet_release(struct socket *sock) |
tcp_close()
当一个套接口正在或已经被关闭,如果在其接收队列有未读数据(不管是在关闭前就已收到的,或者还是在关闭后新到达的),那么此时就需给对端发送一个RST数据包,对应到下面一段代码
1 | if (data_was_unread) {//接受区还有数据没有被读完 |
如果linger结构体的字段l_onoff为1,而l_linger为0
1 | else if (sock_flag(sk, SOCK_LINGER) && !sk->sk_lingertime) { |
下面就是对应正常四次挥手关闭流程,
先调用函数tcp_close_state()切换状态,判断是否需要发送FIN数据包(eg.如果当前还处于TCP_SYN_SENT状态,连接尚未完全建立,自然就不用发送FIN数据包),如果需要发送FIN数据包则调用tcp_send_fin()
1 | ....... |
tcp_send_fin
深入到发送fin内部来看,
如果发送队列还有数据,那么直接将取出末尾数据包,设置FIN。否则分配一个新的skb,最后调用函数__tcp_push_pending_frames() -> tcp_write_xmit()发送数据包。
1 | void tcp_send_fin(struct sock *sk) |
sk_stream_wait_close
这是一个阻塞等待函数,参数timeout指示了等待的时间(单位为时钟滴答)。
while循环的退出点有两处
当前进程收到信号或时间超时(timeout)
sk_wait_event()
1 | void sk_stream_wait_close(struct sock *sk, long timeout) |
至此我们结合源码大致搞清楚了SO_LINGER选项的设置对TCP连接关闭的影响。
SO_REUSEPORT&&SO_REUSEADDR
SO_REUSEADDR和SO_REUSEPORT主要是影响socket绑定ip和port的成功与否。有几点绑定规则主要注意下
规则1:socket可以指定绑定到一个特定的ip和port,例如绑定到192.168.0.11:9000上;
规则2:同时也支持通配绑定方式,即绑定到本地”any address”(例如一个socket绑定为 0.0.0.0:21,那么它同时绑定了所有的本地地址);
规则3:默认情况下,任意两个socket都无法绑定到相同的源IP地址和源端口
SO_REUSEADDR
1、改变了通配绑定时处理源地址冲突的处理方式
so_reuseaddr作用在于允许一个socket 绑定了统配地址+port, 另外一个套接字绑定具体地址+相同端口
1 | SO_REUSEADDR socketA socketB Result |
2、改变了系统对处于TIME_WAIT状态的socket绑定地址的处理
处于time-wait 状态下的套接字需要等待2msl 才能重新使用其绑定的端口与地址,设置了so_reuseaddr没有此限制
SO_REUSEPORT
- 允许将多个socket绑定到相同的地址和端口,前提每个socket绑定前都需设置
- linux内核在处理SO_REUSEPORT socket的集合时,进行了简单的负载均衡操作,即对于UDP socket,内核尝试平均的转发数据报,对于TCP监听socket,内核尝试将新的客户连接请求(由accept返回)平均的交给共享同一地址和端口的socket(监听socket)。
通过设置套接字的SO_REUSEPORT能够用来解决epoll_wait存在的惊群问题,把监听描述符添加到epoll监听事件,多个子进程都epoll_wait阻塞等待,由内核来做负载均衡,这样就避免了当实践发生时同时惊醒多个工作进程,添加了SO_REUSEPORT的模型如下:
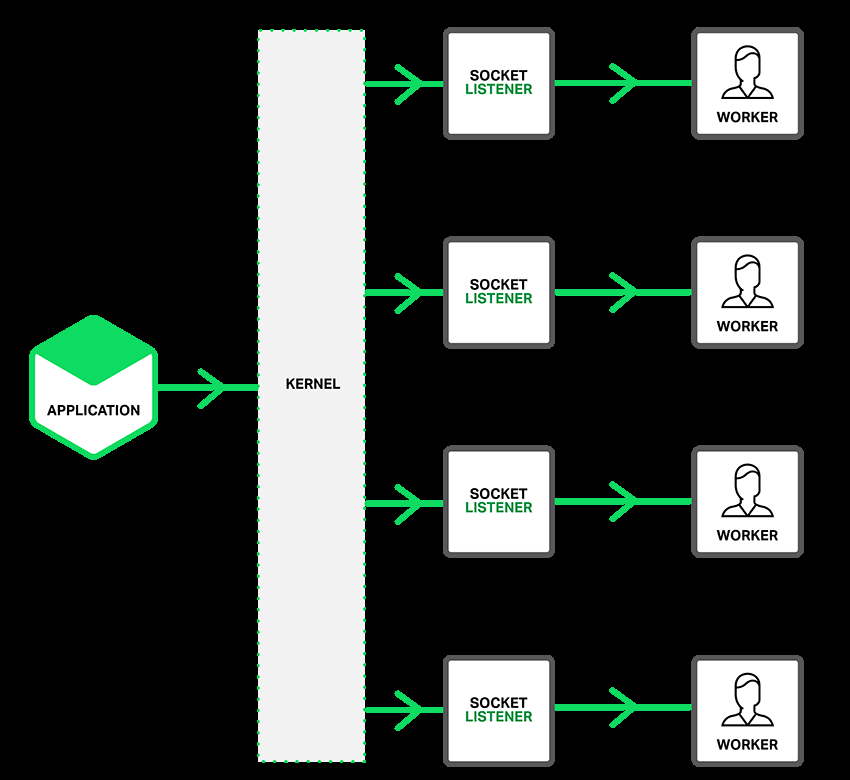
TCP_CORK
tcp_cork与tcp_nodelay 以及nagle 容易搞混,这里我们结合他们的应用场景以及代码来理清楚。
nagle算法
大致思想:
为了提高网络吞吐量,如果发送小数据包,那么20字节包头的负担太大,于是通过将小数据包累积到一个MSS长度再发出来。
同样影响小包发送的套接字选项:TCP_NODELAY,TCP_CORK
Nagle算法的基本定义是任意时刻,最多只能有一个未被确认的小段。 所谓“小段”,指的是小于MSS尺寸的数据块,所谓“未被确认”,是指一个数据块发送出去后,没有收到对方发送的ACK确认该数据已收到。
Nagle算法的规则(tcp_output.c文件里tcp_nagle_check函数注释):
(1)如果包长度达到MSS,则允许发送;
(2)如果该包含有FIN,则允许发送;
(3)设置了TCP_NODELAY选项,则允许发送;
(4)未设置TCP_CORK选项时,若所有发出去的小数据包(包长度小于MSS)均被确认,则允许发送;
(5)上述条件都未满足,但发生了超时(一般为200ms),则立即发送。
TCP_NODELAY是禁用Nagle算法,即数据包立即发送出去,而选项TCP_CORK与此相反,可以认为它是Nagle算法的进一步增强,即阻塞数据包发送,具体点说就是:TCP_CORK选项的功能类似于在发送数据管道出口处插入一个“塞子”,使得发送数据全部被阻塞,直到取消TCP_CORK选项(即拔去塞子)或被阻塞数据长度已超过MSS才将其发送出去。举个对比示例,比如收到接收端的ACK确认后,Nagle算法可以让当前待发送数据包发送出去,即便它的当前长度仍然不够一个MSS,但选项TCP_CORK则会要求继续等待。
TCP_CORK的应用场景
TCP_CORK选项的作用主要是阻塞小数据发送,服务器处理一个客户端请求,发送的响应数据包括响应头和响应体两部分,利用TCP_CORK选项就能让这两部分数据一起发送。
按照之前的分析,设置了CORK之后,有几种可能数据会被发送
- 通过setoptsock关闭TCP_CORK这个选项。
- socket阻塞的数据大于MSS。
- 自从堵上塞子写入第一个字节开始,已经经过200ms。
- socket被关闭。
一旦满足上面的任何一个条件,TCP就会将数据发送出去。对于Server来说,发送HTTP响应既要发送尽量少的segment,同时又要保证低延迟,那么需要在写完数据后显式取消设置TCP_CORK选项,让数据立即发送出去:
1 | int state = 1; |
参考
Nagle 算法与 TCP socket 选项 TCP_CORK