校招期间刷题做的一些笔记,主要配合leetcode, acwing平台使用。
这些题目是20年疫情期间一个一个做的,一开始啥也不会,acwing的一些视频对我算法学习帮助很大。
最近在回顾很多东西,发的日记,印象笔记里面的笔记,这些算法题现在没啥兴趣做了,但是我觉得以后有一天总还是要用得上的。
许知远-罗翔访谈记录
《十三邀》中许对罗翔的访谈,这其中看到了B站张三老师另外的一面
多抓鱼采访
- 多抓鱼和咸鱼区别?
咸鱼更像是一个平台,一个流量入口,对于商品的质量没有过多的把控,当然这也是一种商业模式,通过动态调整容错率,用户的信用来优化。 但是多抓鱼是负责品控的,对于什么书卖不卖有自己的逻辑,同时也会对回收的书做消毒等后期处理,提升整个交易的体验感。
“可能因为多抓鱼是做书的,所以大家对我们经常有一种误解,觉得我们是一家卖情怀的公司,但事实上真不是这样的,我们是一家正经的商业公司。虽然我们的员工都很喜欢看书,也非常喜欢逛二手店,但是我们觉得,想要把一件事情做好,就一定要有一个良好的商业模式在背后支撑,这样才可以走得比较长远,而不是用爱来发电。”
为什么做多抓鱼?
猫助自己大学期间对文化产品需求很高,同时没什么钱,于是在毕业季做起了摆摊。
解决交易信用,解决交易摩擦;用定价系统解决了交易效率的问题,用翻新的技术解决了交易信用的问题
因为我们的员工非常相信一句话:一家书店的气质是由它不卖什么书决定的
二手物品往往有它自己的故事,它都带着上一个主人的回忆,这也是多抓鱼名字的来源,是一个法语单词,déjà vu
安全感不会是你的年薪带给你的,就像曾经的我那样。安全感其实是通过你的创造带给你的
猫助的职业路径从搜狐->知乎->阿里,合伙创始人陈托前知乎商业产品负责人、豆瓣社区开发负责人
“当时的打工让我感受到很多虚无的光环,大公司的title、夸张的年薪,这些跟「你是谁」「你想在世界上做什么」完全没有关系的世俗定位让我很迷失,我很害怕失去这种定位带来的安全感。”
多抓鱼的定价策略

- 确定几类书不收
- 一开始人工判断书收不收,慢慢积累数据集,通过人工智能来判断。
- 定价通过多抓鱼内部数据,根据市场供求关系动态变化
shownotes
适合反复看的技术入门教程
- Kubernetes 入门&进阶实战 腾讯CSIG工程师写的,估计是内部k吧开源出来的
笔者今年(公元 2020 年)9 月从端侧开发转到后台开发,第一个系统开发任务就强依赖了 K8S,加之项目任务重、排期紧,必须马上对 K8S 有概念上的了解。然而,很多所谓“K8S 入门\概念”的文章看的一头雾水,对于大部分新手来说并不友好。经历了几天痛苦地学习之后,回顾来看,K8S 根本不复杂。于是,决心有了这一系列的文章:一方面希望对新手同学有帮助;另一方面,以文会友,希望能够有机会交流讨论技术。
- CMake 入门指南 这位大哥是B站后端工程师,最早是在饭否看到他的技术分享觉得很棒,然后顺藤摸瓜找到了他的个人博客,可以看出来他对C++理解还是很深,虽然我之后可能不怎么会接触C++开发了,但是很多好的概念还是值得学习的。
0x00 起手式
这里假设题主以及其他想入门 CMake 的人像我一样,下面是我个人总结的比较适合的学习路径。
首先默念三遍并记住口诀:
- Declare a target
- Declare target’s traits
- It’s all about targets
然后 clone https://github.com/ttroy50/cmake-examples 这个项目到本地,把里面的
- 01-basic(跳过E-installing,因为和依赖有关,后面会说)
- 02-sub-projects
两个目录认真的学习一遍,最好自己能够动手跟着做一遍。
每学习完一个小节,把前面的三句口诀复习一下
每遇到一个不认识的命令,在 Effective Modern CMake 这个页面里搜索一下,看看这个命令是否取代了某个老命令。
Peter Thiel's Religion — David Perell
bash学习
学习bash
introduction-to-bash-scripting的学习笔记 配合 线上bash解释器
bash 脚本开头一行 都有 #!/bin/bash 指此脚本使用/bin/sh来解释执行,#!是特殊的表示符,其后面根的是此解释此脚本的shell的路径, python脚本在开头也有类似的语句, #!/bin/python2 or #!/bin/python3
创建完一个bash脚本之后,需要通过chmod +x XXX.sh 赋予bash脚本执行权限, 文件的权限可以通过ls -l 查看详细, 用户组,其他,用户都具有自己对文件的权限。
bash 脚本执行可以 通过./XXX.sh 也可以直接指明bash xxx.sh 其中前者指定了sh 文件的路径,参考
变量
bash 变量不需要指定类型,直接赋值,解释器动态解释。
变量定义:
name="DevDojo" note: 赋值号左右不能又空格,如果平时编码习惯和这个不一样,需要注意下。
变量使用
echo ${name} 括号增加可读性。同时变量也可以在表达式中使用,语法与直接使用一样。
bash 语句不像c++需要显式;表示语句结束
用户输入
从命令行读取用户输入
read variable
外部参数
bash 脚本在运行时候,可以跟可变多的参数,在脚本内部用$1, $2来指代,如下面例子
1 |
|
也可以很方便的用 $@ 来引用所有的外部参数.
$0表示脚本文件名,一个用处就是在执行完脚本之后,可以用$0获取脚本名,然后做自删除.
1 |
|
数组
语法:my_array=("value 1" "value 2" "value 3" "value 4") 元素之间用空格隔开
数组引用类似C, echo ${my_array[1]} 元素起始下标为0
数组长度获取
1 | list=(1 2 3 4) |
条件表达式
- 算数表达 语法类似, 用英文字母的缩写来表示比较属性, eg. lt(less than) ,eq(equal) …..
- [[ ${arg1} -eq ${arg2} ]] equal 如果两个变量相同返回true
- 字符串
- [[ -v ${varname} ]] 变量如果被赋值返回true
- [[ -z ${string} ]] 字符串长度为0 为true
- [[ -n ${string} ]] 字符串长度不为0
- 文件表达式 在linux 下面一切都是文件,文件具有不同的类型 比如块文件,字符设备,目录等
- [[ -d ${file} ]] 是否为目录
- [[ -x ${file} ]] 文件是否可执行
- [[ -L ${file} ]] 文件是否为符号链接
有了条件表达式,自然引出了条件语句
条件语句
if-else
1 | if [[ some_test ]] |
swith 语句
1 | case $some_variable in |
注意点
- case 语句用关键字case开始,引用变量,然后加关键字in
- 匹配模式用) 结束
- All clauses have to be terminated by adding ;; at the end
- 默认模式用*匹配
- case 语句结束用esac关键字
循环
while
1 | while [ your_condition ] |
条件表达式都用[] 或者[[]]括起来, 区别
until
含义是当条件不为真时候一直运行
1 | until [ your_condition ] |
谁想看清尘世就应当同它保持必要的距离
《树上的男爵》是一本小册子,200来页,很快就能读完。
书中探讨了关于自我和集体,自我和爱情,以及为了追求一个完整的自我,所作的取舍。要有不少句子都充满哲理,引人深思。
他懂得这个道理:集体会使人更强大,能突出每个人的长处,使人得到替自己办事时极难以获得的那种快乐,会为看到那么多正直、勇敢而能干的人而喜悦,为了他们值得去争取美好的东西(而在为自己而生活时,经常出现的是相反的情形,看到的是人们的另一副面孔,使你必须永远用手握住剑柄)。 这个火灾的夏季因此而成为一个不错的季节:在大家的心中有一个需要解决的共同问题,每个人都把它放在其他个人利益之前,而且从其他许多优秀人物的赞同和敬佩中得到了满足与报偿。 后来,柯希莫不得不明白,当那个共同的问题不存在之后,集体就不再像从前那么好了,做一个孤独的人更好一些,而不要当首领。
真事使人回忆起许多属于过去的时光、细腻的感情、烦扰、幸福、疑惑、光荣和对自己的厌恶,而故事中砍掉了主要的东西,一切显得轻而易举。但变来变去,最后发觉自己在回头去讲自己经历过的真实生活中体验过或发生过的事情。
如果不感到自身充满力量,就不可能有爱情。
套接字选项小结
总结影响网络收发包的一些套接字选项,对一些概念可能理解不对,希望大家多多指教。后面会持续更新ing。
负载均衡大量TW分析
tcp40ms延迟问题分析
背景
tcp抓包发现服务端回复ack存在40ms左右延迟
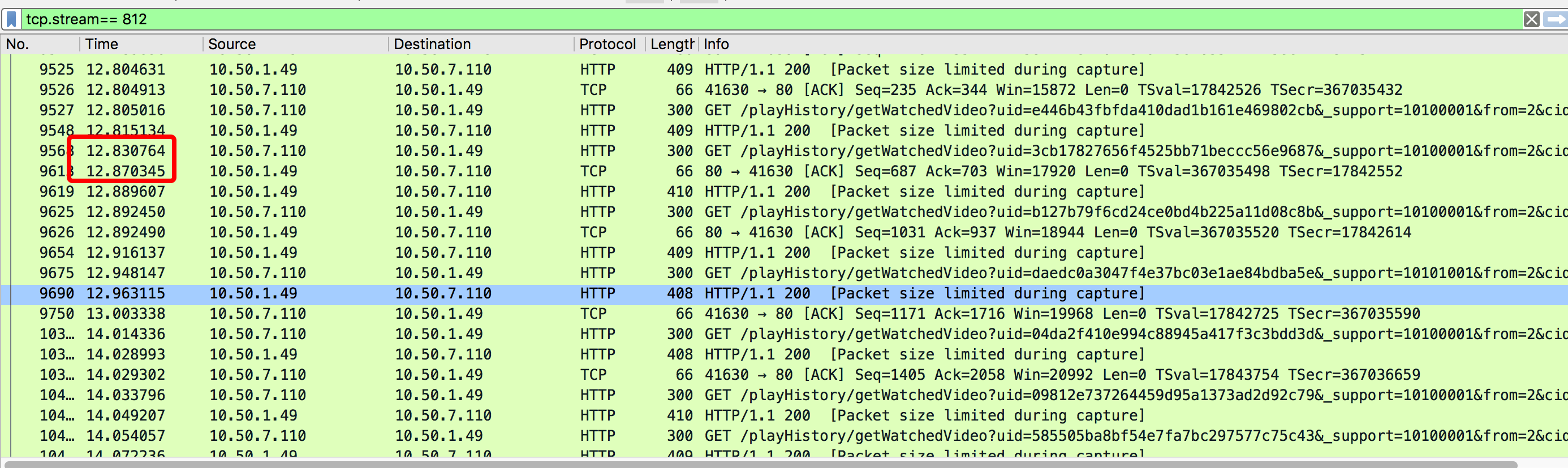
问题排查过程
通过查阅资料发现tcp40ms延迟不是一个偶然的现象。先给出结论:客户端开启nagle算法+服务端延迟ack,延迟ack的超时时间为40ms。
先介绍下重要的概念
delay ack
在TCP建立连接之后,最开始的数据交互是处于quick ack mode,顾名思义就是当对端收到数据立马就会回复ack。在接下来的数据交互过程中,服务端仍然执行快速ack,服务端然后往对端发送交互数据,此时系统探测到了这样一种交互行为,于是开启ping pong mode。服务端开启了ping pong mode之后,收到数据不会立马回复对端ack,而是在回复响应数据时候带上ack,这样减少了网络中的包量。但是如果服务端在延时ack时间都没有响应客户端的请求就可能出现短暂的响应延迟。
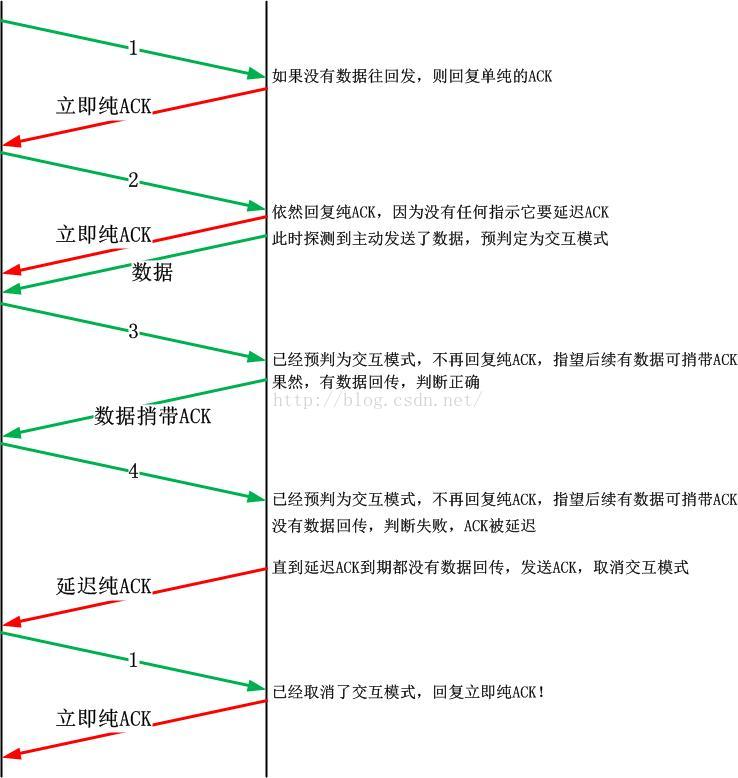
nagle算法
Nagle算法的基本定义是任意时刻,最多只能有一个未被确认的小段。 所谓“小段”,指的是小于MSS尺寸的数据块,所谓“未被确认”,是指一个数据块发送出去后,没有收到对方发送的ACK确认该数据已收到。
Nagle算法的规则(tcp_output.c文件里tcp_nagle_check函数注释):
(1)如果包长度达到MSS,则允许发送;
(2)如果该包含有FIN,则允许发送;
(3)设置了TCP_NODELAY选项,则允许发送;
(4)未设置TCP_CORK选项时,若所有发出去的小数据包(包长度小于MSS)均被确认,则允许发送;
(5)上述条件都未满足,但发生了超时(一般为200ms),则立即发送。
有了上面的知识铺垫,我们具体分析下客户端开启nagle,服务端处于delay ack 状态下,客户端不同大小数据请求下延时情况。
- 当客户端请求数据小于mss大小
假设客户端之前的数据已经全部被ack了,此时发送一个新的数据请求,小于mss,对端服务器在收到数据之后,不会立马回复ack,但是在delay ack超时之前能够回复响应数据,顺带就把ack发过去了,所以不会出现我们说的40ms延迟。
- 客户端请求数据大于mss
由于请求数据大于mss,一个包装不下这么多数据,tcp会将数据分成小包发送,在发送第一个小包之后,服务端延迟ack,同时由于数据不全,服务端不能立即响应,于是就在等待延迟ack超时,同时客户端这边开启了nagle,之前发送的数据包还没有被ack,待发送的数据包小于mss,于是也进入等待,这样一来双方都处于等待,进入了短暂的”死锁“。
解决方案
有了上面的分析,我们可以从两个方向来考虑如何解决40ms延迟。
服务端关闭延迟ack ;
echo 1 > /proc/sys/net/ipv4/tcp_no_delay_ack客户端关闭nagle;通过设置
TCP_NODELAY来实现