linux网络协议栈学习小结
前言
下面的包分析基于下面的TCP/IP四层协议栈,内核代码基于2.6版本。
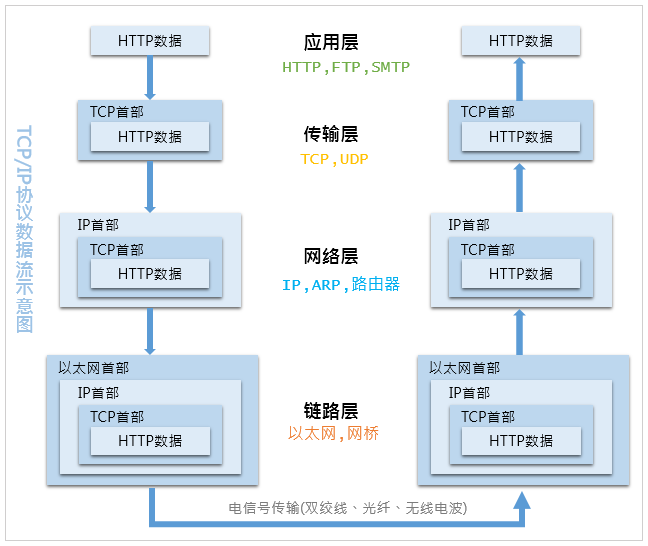
发包过程
应用层
应用层是数据包发送起始点, 应用进程通过套接字API发起写系统调用。对套接字做读写操作,和对普通文件做读写操作相似,在linux中万物皆是文件。
常用的写套接字API如下
1 | ssize_t send(int sockfd, const void *buf, size_t len, int flags); |
其中send,write,writev只能用于面向连接的套接字(SO_STREAM)。
writev()可以指定一系列的缓冲区,收集要写的数据,使可以安排数据保存在多个缓冲区中,然后同时写出去,从而避免出现Nagle和延迟ACK算法的相互影响,起到类似”gather write”的效果。
struct iovec结构如下
1 | struct iovec { |
上述的套接字API接口处理流程相似
- 输入参数都是描述符,我们需要将
fd-> struct sock。 - 创建消息头部,套接字控制信息(uid,pid,…)
无论我们通过write还是sendmsg等写操作,最后都会到sock_senmsg()
1 | int sock_sendmsg(struct socket *sock, struct msghdr *msg, size_t size) |
__sock_sendmsg()做了一些安全检查之后,会调用协议相关的消息发送函数sock->ops->sendmsg(iocb, sock, msg, size),协议相关的 操作集在套接字创建过程通过type,family初始化。举个例子,如果是一个TCP套接字,那么实际将调用tcp_sendmsg,如果是一个UDP套接字,将调用udp_sendmsg。
套接字接口层
我们在实际做网络通信过程中,一般需要经过这几个步骤
- 通过
socket()创建套接字 bind()绑定套接字listen()监听套接字
这里详细参考我的这篇文章 socket从创建到连接过程小结
传输层
TCP 栈简要过程:
tcp_sendmsg 函数会首先检查已经建立的 TCP connection 的状态,然后获取该连接的 MSS,开始 segement 发送流程。
构造 TCP 段的 playload:它在内核空间中创建该 packet 的 sk_buffer 数据结构的实例 skb,从 userspace buffer 中拷贝 packet 的数据到 skb 的 buffer。
构造 TCP header。
计算 TCP 校验和(checksum)和 顺序号 (sequence number)。
TCP 校验和是一个端到端的校验和,由发送端计算,然后由接收端验证。其目的是为了发现 TCP 首部和数据在发送端到接收端之间发生的任何改动。如果接收方检测到校验和有差错,则 TCP 段会被直接丢弃。TCP 校验和覆盖 TCP 首部和 TCP 数据。
发到 IP 层处理:调用 IP handler 句柄 ip_queue_xmit,将 skb 传入 IP 处理流程。
具体到一些细节
tcp_sendmsg(struct kiocb *iocb, struct sock *sk, struct msghdr *msg,size_t size)
按照之前的分析,sock_sendmsg最终调用tcp_sendmsg,我们知道TCP是一个面向连接的协议,因此在发送数据之前,内核会检查TCP的连接状态。
1 | /* Wait for a connection to finish. */ |
从上面的代码可以发现,如果连接尚未建立,不处于ESTABLISHED或者CLOSE_WAIT状态,那么进程进行睡眠,等待三次握手的完成。被动关闭方收到FIN,处于CLOSE_WAIT状态,此时处于半关闭状态,仍然可以发数据(不要错看成TIME-WAIT)了。
tcp建立连接
在传输数据之前,tcp作为面向连接的协议,需要先通过三次握手来建立连接。篇文章是很好的 参考
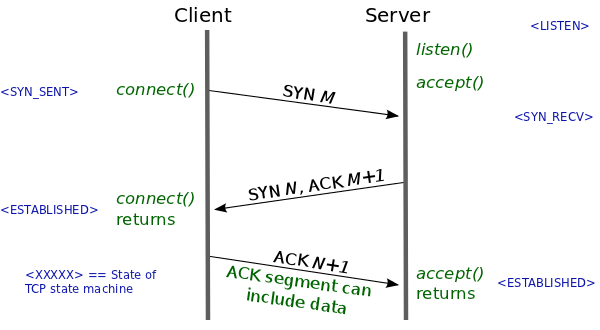
tcp_senmsg
一旦连接建立好,tcp_sendmsg()先做了发包之前的准备工作,比如获取mss(maxium segment size),mss规定了一次发送的最大数据大小,mss的值一般为1460byte,因为数据链路层的MTU一般为1500byte,mss加上tcp,ip头部即得到MTU。
具体到发送数据,这里第一次涉及到用户空间数据到内核空间的拷贝, 内核先分配struct sk_buff。 如果skb的线性数据区还有剩余空间,就复制用户进程数据到线性数据区中,如果线性区域使用完,就使用分页区域, 通过skb copy to page拷贝用户空间的数据到skb的分页中,同时计算校验和。
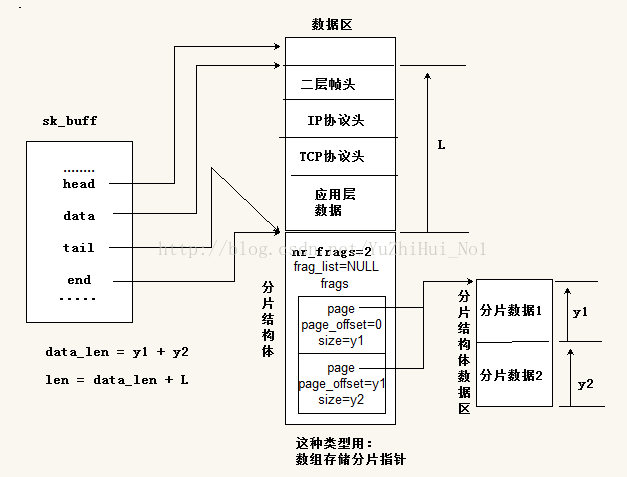
sk_buff
这里看下sk_buff中线性区域和非线性区域具体细节。
有四个指针,标识线性区域,(head,end)表示分配的缓存范围,(data,tail)表示实际数据的范围。head指针和end指针指向的位置一直都不变,对于数据的变化和协议信息的添加都是通过data指针和tail指针的改变来表现的。
sk_buff中有几个长度很容易搞混,这里梳理一下
1 | sk_buff->data_len ;分片中数据的长度,即是分片结构体中page指向的数据区长度 |
下面的图大致描述了sk_buff结构
tcp_transmit_skbs
tcp_sendmsg最终通过调用tcp_transmit_skb 将数据包传到IP层。这里面主要做了这几件事情。首先,sk_buff是没有头部信息的,我们需要自己构造TCP头部,包含了源端口,目的端口,序列号等。与头部相关的数据结构为struct scphdr,定义如下。
1 | struct tcphdr { |
我们发现结构体的布局和大小端是有关系的,但是只涉及到标志位。
字节序和比特序
先问自己一个问题
上述代码如果不添加条件编译语句,为什么不具有移植性?
字节序的最小单位是1个字节,位域的最小单位是一个位域字段。
位域,也就是变量后面跟上冒号接数字表示这个变量占几个比特位的这种字段,比如:__u16 res1:4这表示ihl只占用了4个比特位。由于位域并不固定几个比特位,所以系统没法提供基于位域的大小端转换函数(htons,htonl.etc)。
之所以offset以及FIN等标志位要按照大端,小端字节序判断,就是为了使得主机无论是大端还是小端,offset相对fin标志位总是处于内存低地址处。
在tcp_transmit_skb 中实际填充tcp头部的过程如下,将seq,ack_seq做了主机字节序到网络字节序的转化。计算tcp头部检验和。
1 | struct tcphdr *th; |
具体看下检验和是如何计算的,发现除了用到tcp头部的信息,还有用到发送端,接收端的ip地址,这么做的目的是因为TCP头部不包含这些信息,为了提高检验能力,我们在计算checksum时,人为的加上一个”伪首部”,伪首部并不会在网络中传输。
1 | void tcp_v4_send_check(struct sock *sk, struct tcphdr *th, int len,struct sk_buff *skb) |
最终通过调用queue_xmit将待发送数据添加到待发送队列。 发送队列的具体位置如下图
IP层
对于单播发包,函数调用的流程图如下:
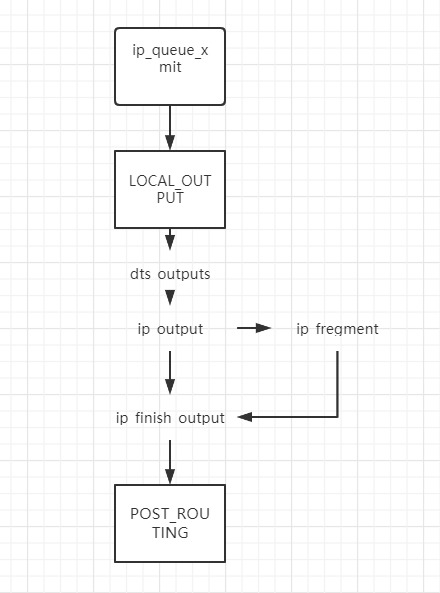
上图可以看到,当 L4 层有数据包待发送时,对于TCP包它将调用ip_queue_xmit它们将这些包交由NETFILTER( LOLACL_OUT)处理后,然后交给 dst_output,这会根据是多播或单播选择合适的发送函数。如果是单播,它会调用 ip_output(),然后是 ip_finish_output(),这个函数主要是检查待发送的数据包大小是否超过 MTU,如果是,则要首先调用 ip_fragment()将其分片,然后再传给 ip_finish_output2(),由它交给链路层处理了。
IP层在TCP数据包的基础上,主要做下面几件事情
- 构建IP头部
- 路由查询以及维护TTL(time to live)
- 包分片
- Netfilter与iptabels做防火墙过滤
如果数据包发送的目的端是本机应用程序,那么数据包将不经过底层协议栈,直接到接收方的TCP层。
分片细节
总的思路就是当L4层传过来的包大于MTU,通过循环,每次分配一个skb,然后将原来skb里面的IP头部部分数据拷贝到新分配的skb中,不同分片的标识号是一样的,不同之处在分片中起始数据相对原始报文的偏移,以及MF(more fregment)等一些标志位。
这里主要关注不同分片IP头部中offset如何设置
1 | /* linux-2.6.11\net\ipv4\ip_output.c*/ |
ip_queue_xmit
tcp层最中通过tp->af_specific->queue_xmit(skb, 0);将数据包传到了IP层,具体到TCP协议,就是调用ip_queue_xmit
- 调用
__sk_dst_check对路由信息做检查 - 调用
ip_route_output_flow,这里是实际做路由计算的点,调用__ip_route_output_key来查找一条路径,使用struct flowi来记录路由查询信息,首先从缓存中查找,如果没找到就从FIB里面找(Forwarding Information Base)
在做路由的过程中,可能会有下面几种可能
- 包继续forwarded, 到ip_forward
- 包路由失败,不能解析,到ip_output
- 包路由解析成功,到dev_queue_xmit
假设我们成功做了路由解析,找到了一条到目的端路径,那么就通过dev_queue_xmit到了数据链路层。
Netfilter
在数据流中什么位置(过滤点)对数据包做什么操作(规则)。
- 过滤点(chain),输入,输出,转发,路由前,路由后
- 过滤规则:
- filter
- nat
- magle
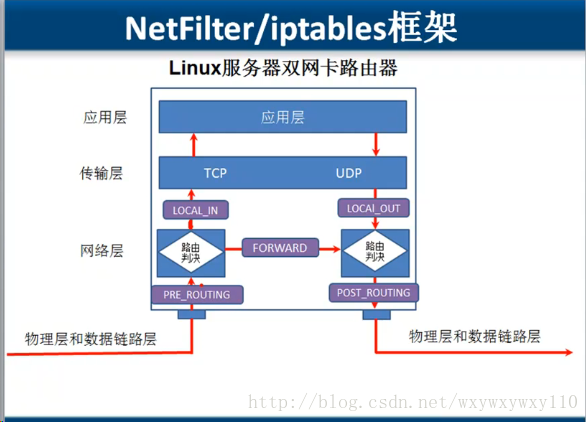
- 当数据包从物理层和数据链路层传输过来,如果数据包是访问Linux主机本身。则经过PRE_ROUTING和LOCAL_IN钩子函数,到达传输层和应用层。
- 当数据包从物理层和数据链路层传输过来,如果数据包需要转发,则经过PRE_ROUTING、FORWARD和POST_ROUTING三个钩子函数。
- 当数据包从Linux主机本身向外发送数据包,要经过LOCAL_OUT和POST_ROUTING钩子函数。
以发数据为例,本地产生的数据经过HOOK函数NF_IP_LOCAL_OUT 处理后,进行路由选择处理,然后经过NF_IP_POST_ROUTING处理后发送出去。
hook原理
所有的回调函数都注册在二维数组全局变量struct list_head nf_hooks[NFPROTO_NUMPROTO][NF_MAX_HOOKS] __read_mostly;中。。数组的第一个维度是注册回调函数的协议族,第二个维度是注册回调函数的hook点,也就是每一个协议族的每一个hook点都是一个双向链表连接的一组回调函数。
当代码执行到HOOK点根据协议类型, HOOK点编号,来遍历执行对应链表所有注册的回调函数,hook点回调函数处理完毕并允许下一步逻辑执行时,okfn被执行。
1 | NF_HOOK(pf, hook, skb, indev, outdev, okfn) |
数据链路层
数据链路层负责将ip层的数据加上包头,发送给网卡。
dev_queue_xmit
在这个函数中,一开始通过屏蔽所有的软中断(buttom-half)来获得设备的队列锁,接着调用qdisc_run()检查设备是否数据包需要传输,如果设备忙,那么该函数将再次在软中断中被调用。qdisc_restart获取设备的xmit锁,如果成功就调用dev->hard_start_xmit来完成最终的数据包传输,这个调用是和具体的设备有关系。一旦网卡完成报文发送,将产生中断通知 CPU,然后驱动层中的中断处理程序就可以删除保存的 skb 了。
网卡中断收发包机制
一般的当网卡有数据到来,通过产生一个硬件中断来通知CPU处理,在运行中断服务历程(ISR)时候,将屏蔽所有中断,也就意味着在执行硬件中断服务时候,不能被抢占,如果中断服务处理的任务比较轻,比如响应键盘等,这个是没有问题的。但是,网卡的中断需要处理的任务是很重的,比如说分配缓存结构体sk_buff,将接收数据拷贝到sk_buff等等,中断服务在处理这些任务时候占用了大量的CPU时间,导致不能及时相应其他的中断。
为了解决上述的问题,linux将中断的处理分为两个步骤top-half,buttom-half。其主要区别就在于上半部分执行的时候禁止一些或者全部中断,下半部分执行期间中断是打开的,可以响应所有中断。上半部分一定运行在中断上下文中,下半部分有很多种实现方式,根据不同的实现方式可能运行在中断上下文中,也可能运行在任务(process)上下文中。上半部分实际响应request_irq(),下半部分推迟实现,以软中断为例,在上半部分硬件中断返回后标记,然后触发软中断。(这一块具体可以参考《内核设计与实现》第八章)
小结
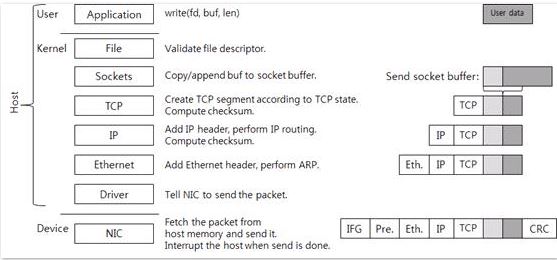
下图总结了数据从用户态拷贝到内核,然后经过内核协议栈到最后网卡发送的整个流程。
小知识点
struct inet_sock是INET域专用的一个socket表示,它是在struct sock的基础上进行的扩展,在基本socket的属性已具备的基础上,struct inet_sock提供了INET域专有的一些属性,比如TTL,组播列表,IP地址,端口等。
网卡多队列
概念:一张网卡具有多个接收队列
解决问题
每个cpu有一个软中断线程对应网卡收包,当网卡流量特别大情况下,就会导致cpu负载高,性能存在瓶颈;
工作原理
网卡多任务队列将收到的包根据四元组信息做哈希运算,然后放到多队列其中一个,之后该连接所有的包都将经过相同队列,每个队列对应不同cpu的软中断,这样就实现了网卡收包的负载均衡,避免了某些cpu负载特别高。
参考
《understading linux kernel internals》